Laura Trotta explains why risk-based quality management is the best strategy to ensure data integrity of information from investigator-led clinical trials.
Introduction
Evidence generated by clinical trials, particularly randomised controlled trials (RCTs), is vital to inform medical practice. Considered the gold-standard approach for evaluating therapeutic interventions, RCTs allow for inferences about causal links between treatment and outcomes.1 Some trials are initiated by industry sponsors, such as pharmaceutical companies or clinical research organisations (CROs), whereas others, investigator-led trials, originate within research sites. The difference between the two usually centres on purpose. Industry-sponsored trials investigate experimental drugs with largely unknown effects and typically have an explanatory approach. They tend to be suitable for the development of novel agents or combinations. Whereas, investigator-led studies are more pragmatic; they usually investigate the benefits and harms of treatments in routine clinical practice. Table 1 characterises some of the contrasts between an explanatory and a pragmatic approach to clinical trials.
This webinar showcases the Growth Direct System; an RMM (Rapid Microbial Method) that improves on traditional membrane filtration, delivering increased accuracy, a faster time to result, enhanced data integrity compliance, and more control over the manufacturing process.
Key learning points:
Understand the benefits of full workflow microbiology quality control testing automation in radiopharmaceutical production
Learn about ITM’s implementation journey and considerations when evaluating the technology
Find out how the advanced optics and microcolony detection capabilities of Growth Direct® technology impact time to result (TTR).
Don’t miss your chance to learn from experts in the industry –Register for FREE
Can’t attend live? No worries – register to receive the recording post-event.
Table 1: Explanatory versus pragmatic approach to clinical trials2
Approach
Explanatory
Pragmatic
Type of trial
Industry-sponsored
Investigator-led
Primary purpose of trial
Regulatory approval
Public health impact
Patient selection
Fittest patients
All patients
Effect of interest
“Ideal” treatment effect
Actual treatment effect
Endpoint ascertainment
Centrally reviewed
Per local investigator
Preferred control group
Untreated (when feasible)
Current standard of care
Experimental conditions
Strictly controlled
Clinical routine
Volume of data collected
Large, for supportive analyses
Key data only
Data quality control
Extensive and on-site
Limited and central only
Industry-sponsored trials are usually highly efficient and benefit from pharma’s highly organised structures, both in terms of safety and regulatory compliance. Yet commercial interests and market expectations mean they may not always address all patients’ needs. Strictness of the eligibility criteria, the choice of comparators, effect size of interest and outcomes, as well as insufficient data on long-term toxicity, can all be restrictive.3 Arguably, the general principles underlying marketing approval by regulatory agencies, such as the Japanese Pharmaceutical and Medical Devices Agency (PMDA), the European Medicines Agency (EMA) and the US Food and Drug Administration (FDA) contribute to these limitations.
Shining a light on investigator‑led clinical trials
Whether a new drug is sufficiently safe and effective for clinical use needs careful review. It requires meticulous assessment of the quality of the pivotal trial design, conduct, data and analysis. However, additional post-approval evidence on novel drugs or devices is still needed to provide a full understanding of the effectiveness and safety of competing interventions in ‘real life’. Investigator-led clinical trials allow for the assessment of patients and settings not necessarily covered by the initial approval, leading to potential extensions of indications and refinement of the drug usage in patient subgroups. Even for newly approved drugs, many questions of clinical interest typically remain unanswered at the time of approval, including the duration of therapy, dose or schedule modifications that may lead to a better benefit/risk ratio, combinations of the new drug with existing regimens, etc.
Equally, repurposing of existing drugs, whose safety and efficacy profile is well documented in other indications, is often less complicated in investigator-led trials when compared to pharmaceutical companies that might have a product that ceases to be financially attractive towards the end of its life-cycle. In addition, large, simple trials that address questions of major public health importance have been advocated for decades as one of the pillars of evidence-based medicine.4
Crucially, more and larger investigator-led trials are required and it is essential to identify ways of conducting them as cost-effectively as possible. Investigator-led clinical trials have particular merit in the field of oncology, offering the potential to generate much of the evidence upon which the treatment of cancer patients is decided. Yet investigator-led trials may be under threat because of excessive regulation and bureaucracy and the accompanying costs. In addition, the contrasts between industry-led and investigator-led trials have direct implications on their conduct, notably with regards to ways of ensuring their quality.
Spiralling costs
…investigator-led trials should collect radically simpler data than industry-sponsored trials”
Clinical trial costs are rising. Recent estimates suggest that pivotal clinical trials leading to FDA approval have a median cost of $19 million; such costs are even higher in oncology and cardiovascular medicine, as well as in trials with a long-term clinical outcome, such as survival.3 In industry-sponsored trials, vast resources are spent in making sure that the data collected are error free. This is typically done via on-site monitoring (site visits) including source-data verification (SDV) and other types of quality assurance procedures, together with centralised monitoring including data management and statistical monitoring. While some on-site activities make intuitive sense, their cost has become exorbitant in the large multicentre trials that are typically required for the approval of new therapies. It has been estimated that for large, global clinical trials, leaving aside site payments, the cost of on-site monitoring represents around 60 percent of the total trial.4
The solution: RBQM
If monitoring activities significantly impacted patient safety or results, then high costs could be justified. Yet there is little evidence showing that extensive, intensive data monitoring has any major impact on the quality of clinical trial data. The most time-consuming and least efficient activity is source data verification (SDV), which can take up to 50 percent of the time spent for on-site visits. The monitoring of clinical trials needs to be re-engineered, not just for investigator-led trials, but also for industry-sponsored trials. To instigate and support this much-needed transition, regulatory agencies worldwide have advocated the use of risk-based quality management (RBQM), including risk-based monitoring (RBM) and central statistical monitoring (CSM).5,6
The central principle of RBQM is to “focus on things that matter”. What matters for a randomised clinical trial is to provide a reliable estimate of the difference in efficacy and tolerance between the treatments being compared. Crucially the criteria to assess efficacy and tolerance may differ between industry-sponsored trials and investigator-led trials.
In terms of safety, investigator-led trials can collect much simpler data than industry-sponsored trials of drugs for which safety has not yet been demonstrated. Typically, in investigator-led trials, the occurrence of Common Terminology Criteria for Adverse Events grade three or grade four toxicities will suffice, plus any unexpected toxicity not known to be associated with the drug being investigated. Finally, medical history and concomitant medications, which may be important to document drug interactions with an experimental treatment, serve no useful purpose in investigator-led trials. All in all, investigator-led trials should collect radically simpler data than industry-sponsored trials.
Equally, data quality needs to be evaluated in a “fit for purpose” manner. While it may be required to attempt to reach 100 percent accuracy in all the data collected for a pivotal trial of an experimental treatment, such a high bar is by no means required for investigator-led trials, as long as no systematic bias is at play to create data differences between the randomised treatment groups (for instance, a higher proportion of missing data in one group than in the other). Both types of trials may benefit from CSM of the data:
industry-sponsored trials to target centres that are detected as having potential data quality issues, which may require an on-site audit
investigator-led trials as the primary method for checking data quality.
Understanding CSM
CSM is a vital part of RBQM. As shown in Figure 1, the process starts with a Risk Assessment and Categorisation Tool (RACT). CSM helps quality management by providing statistical indicators of quality based on data collected in the trial from all sources. A “Data Quality Assessment” of multicentre trials can be based on the simple statistical idea that data should be broadly comparable across all centres. This idea is grounded in the fact that data consistency is an acceptable surrogate for data quality. Other additional tools of central monitoring can be used to uncover situations in which data issues occur in most (or sometimes all) centres, such as “Key Risk Indicators” and “Quality Tolerance Limits”. Taken together, all these tools produce statistical signals that may reveal issues in specific centres.
Figure 1: The Risk-Based Quality Management process
Actions must then be taken to address these issues, such as contacting the centre for clarification or in some cases performing an on-site audit to understand the cause of the data issue. Although it is a simple idea to perform a central data quality assessment based on the consistency of data across all centres, the statistical models required to implement the idea are necessarily complex to properly account for the natural variability in the data. Essentially, a central data quality assessment is efficient if:
Data have undergone basic management checks, whether automated or manual, to eliminate obvious errors (such as out-of-range or impossible values) that can be detected and corrected without a statistical approach
Data quality issues are limited to a few centres, while the other centres have data of good quality
All data are used, rather than a few key data items such as those for the primary endpoint or major safety variables
Many statistical tests are performed, rather than just a few obvious ones such as a shift in mean or a difference in variability.
The last two points are worth highlighting. It is statistically preferable to run many tests on all data collected than on a few data items carefully selected for their relevance or importance. Volume rather than clinical relevance is crucial for a reliable statistical assessment of data quality. The power of statistical detection comes from an accumulation of evidence, which would not be available if only important items and standard tests were considered. In addition, investigators pay more attention to key data (such as the primary efficacy endpoint or important safety variables), which therefore do not constitute reliable indicators of overall data quality. Nevertheless, careful checks of key data are also essential, although such checks generally are not statistical in nature.
CSM in use
Experience from actual trials as well as extensive simulation studies has shown that a statistical data quality assessment is effective at detecting issues with study conduct and data reliability. Experience from actual trials suggests that such study issues can be broadly classified as:
Fraud, such as fabricating patient records or even fabricating entire patients
Data tampering, such as filling in missing data or propagating data from one visit to the next
Sloppiness, such as not reporting some adverse events, making transcription errors, etc
Miscalibration or other problems with automated equipment.
Whilst these data errors impact trial results in different ways, all of them can potentially be detected using CSM, at a far lower cost and with much higher effectiveness than through labour-intensive methods such as SDV and other on-site data reviews. Investigator-led trials generate more than half of all randomised evidence on new treatments and it seems essential that this evidence be submitted to statistical quality checks before going to print and influencing clinical practice.
Conclusion
Investigator-led clinical trials are pragmatic trials that aim to investigate the benefits and harms of treatments in routine clinical practice. These much-needed trials represent most trials currently conducted. They are however threatened by the rising costs of clinical research, which are in part due to extensive trial monitoring processes that focus on unimportant details. Conversely, RBQM focuses instead on “things that really matter”. CSM plays a crucial role in RBQM, helping to drive down the cost of randomised clinical trials, especially investigator-led trials, while simultaneously improving their quality.
About the author
Dr Laura Trotta joined CluePoints in 2015 and moved into her current role as R&D manager in 2018, where she leads a team of data scientists responsible for developing new statistical and machine learning algorithms to assess the quality, accuracy and integrity of clinical trial data. Laura holds a Master’s degree in Biomedical Engineering and a PhD in Applied Mathematics from the University of Liège, Belgium.
References
Collins R, Bowman L, Landray M, et al (2020) The magic of randomization versus the myth of real-world evidence. N Engl J Med 382:674–678
Buyse M, Trotta L, Saad E, at al (2020) Central statistical monitoring of investigator‑led clinical trials in Int. J. Clin. Oncol 25:1207–1214
Naci H, Davis C, Savovic J et al (2019) Design characteristics, risk of bias, and reporting of randomised controlled trials supporting approvals of cancer drugs by European Medicines Agency, 2014–16: cross sectional analysis. BMJ 366:5221
Yusuf S, Collins R, Peto R (1984) Why do we need some large, simple randomized trials? Stat Med 3:409–422
Moore TJ, Zhang H, Anderson G, et al (2018) Estimated costs of pivotal trials for novel therapeutic agents approved by the US Food and Drug Administration, 2015–2016. JAMA Intern Med 178:1451–1457
Institute of Medicine (US) (2010) Forum on drug discovery development and translation. Transforming Clinical Research in the United States. National Academies Press, Washington DC
European Medicines Agency (2011) Reflection paper on risk based quality management in clinical trials. Eur Med 1:94–103
S. Department of Health and Human Services (2013) Food and drug administration guidance for industry. Oversight of Clinical Investigations. A Risk-Based Approach to Monitoring. National Academies Press, DC
This website uses cookies to enable, optimise and analyse site operations, as well as to provide personalised content and allow you to connect to social media. By clicking "I agree" you consent to the use of cookies for non-essential functions and the related processing of personal data. You can adjust your cookie and associated data processing preferences at any time via our "Cookie Settings". Please view our Cookie Policy to learn more about the use of cookies on our website.
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorised as ”Necessary” are stored on your browser as they are as essential for the working of basic functionalities of the website. For our other types of cookies “Advertising & Targeting”, “Analytics” and “Performance”, these help us analyse and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these different types of cookies. But opting out of some of these cookies may have an effect on your browsing experience. You can adjust the available sliders to ‘Enabled’ or ‘Disabled’, then click ‘Save and Accept’. View our Cookie Policy page.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Cookie
Description
cookielawinfo-checkbox-advertising-targeting
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Advertising & Targeting".
cookielawinfo-checkbox-analytics
This cookie is set by GDPR Cookie Consent WordPress Plugin. The cookie is used to remember the user consent for the cookies under the category "Analytics".
cookielawinfo-checkbox-necessary
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
This cookie is set by GDPR Cookie Consent WordPress Plugin. The cookie is used to remember the user consent for the cookies under the category "Performance".
PHPSESSID
This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed.
viewed_cookie_policy
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
zmember_logged
This session cookie is served by our membership/subscription system and controls whether you are able to see content which is only available to logged in users.
Performance cookies are includes cookies that deliver enhanced functionalities of the website, such as caching. These cookies do not store any personal information.
Cookie
Description
cf_ob_info
This cookie is set by Cloudflare content delivery network and, in conjunction with the cookie 'cf_use_ob', is used to determine whether it should continue serving “Always Online” until the cookie expires.
cf_use_ob
This cookie is set by Cloudflare content delivery network and is used to determine whether it should continue serving “Always Online” until the cookie expires.
free_subscription_only
This session cookie is served by our membership/subscription system and controls which types of content you are able to access.
ls_smartpush
This cookie is set by Litespeed Server and allows the server to store settings to help improve performance of the site.
one_signal_sdk_db
This cookie is set by OneSignal push notifications and is used for storing user preferences in connection with their notification permission status.
YSC
This cookie is set by Youtube and is used to track the views of embedded videos.
Analytics cookies collect information about your use of the content, and in combination with previously collected information, are used to measure, understand, and report on your usage of this website.
Cookie
Description
bcookie
This cookie is set by LinkedIn. The purpose of the cookie is to enable LinkedIn functionalities on the page.
GPS
This cookie is set by YouTube and registers a unique ID for tracking users based on their geographical location
lang
This cookie is set by LinkedIn and is used to store the language preferences of a user to serve up content in that stored language the next time user visit the website.
lidc
This cookie is set by LinkedIn and used for routing.
lissc
This cookie is set by LinkedIn share Buttons and ad tags.
vuid
We embed videos from our official Vimeo channel. When you press play, Vimeo will drop third party cookies to enable the video to play and to see how long a viewer has watched the video. This cookie does not track individuals.
wow.anonymousId
This cookie is set by Spotler and tracks an anonymous visitor ID.
wow.schedule
This cookie is set by Spotler and enables it to track the Load Balance Session Queue.
wow.session
This cookie is set by Spotler to track the Internet Information Services (IIS) session state.
wow.utmvalues
This cookie is set by Spotler and stores the UTM values for the session. UTM values are specific text strings that are appended to URLs that allow Communigator to track the URLs and the UTM values when they get clicked on.
_ga
This cookie is set by Google Analytics and is used to calculate visitor, session, campaign data and keep track of site usage for the site's analytics report. It stores information anonymously and assign a randomly generated number to identify unique visitors.
_gat
This cookies is set by Google Universal Analytics to throttle the request rate to limit the collection of data on high traffic sites.
_gid
This cookie is set by Google Analytics and is used to store information of how visitors use a website and helps in creating an analytics report of how the website is doing. The data collected including the number visitors, the source where they have come from, and the pages visited in an anonymous form.
Advertising and targeting cookies help us provide our visitors with relevant ads and marketing campaigns.
Cookie
Description
advanced_ads_browser_width
This cookie is set by Advanced Ads and measures the browser width.
advanced_ads_page_impressions
This cookie is set by Advanced Ads and measures the number of previous page impressions.
advanced_ads_pro_server_info
This cookie is set by Advanced Ads and sets geo-location, user role and user capabilities. It is used by cache busting in Advanced Ads Pro when the appropriate visitor conditions are used.
advanced_ads_pro_visitor_referrer
This cookie is set by Advanced Ads and sets the referrer URL.
bscookie
This cookie is a browser ID cookie set by LinkedIn share Buttons and ad tags.
IDE
This cookie is set by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
li_sugr
This cookie is set by LinkedIn and is used for tracking.
UserMatchHistory
This cookie is set by Linkedin and is used to track visitors on multiple websites, in order to present relevant advertisement based on the visitor's preferences.
VISITOR_INFO1_LIVE
This cookie is set by YouTube. Used to track the information of the embedded YouTube videos on a website.



 Whether a new drug is sufficiently safe and effective for clinical use needs careful review. It requires meticulous assessment of the quality of the pivotal trial design, conduct, data and analysis. However, additional post-approval evidence on novel drugs or devices is still needed to provide a full understanding of the effectiveness and safety of competing interventions in ‘real life’. Investigator-led clinical trials allow for the assessment of patients and settings not necessarily covered by the initial approval, leading to potential extensions of indications and refinement of the drug usage in patient subgroups. Even for newly approved drugs, many questions of clinical interest typically remain unanswered at the time of approval, including the duration of therapy, dose or schedule modifications that may lead to a better benefit/risk ratio, combinations of the new drug with existing regimens, etc.
Whether a new drug is sufficiently safe and effective for clinical use needs careful review. It requires meticulous assessment of the quality of the pivotal trial design, conduct, data and analysis. However, additional post-approval evidence on novel drugs or devices is still needed to provide a full understanding of the effectiveness and safety of competing interventions in ‘real life’. Investigator-led clinical trials allow for the assessment of patients and settings not necessarily covered by the initial approval, leading to potential extensions of indications and refinement of the drug usage in patient subgroups. Even for newly approved drugs, many questions of clinical interest typically remain unanswered at the time of approval, including the duration of therapy, dose or schedule modifications that may lead to a better benefit/risk ratio, combinations of the new drug with existing regimens, etc. In terms of safety, investigator-led trials can collect much simpler data than industry-sponsored trials of drugs for which safety has not yet been demonstrated. Typically, in investigator-led trials, the occurrence of Common Terminology Criteria for Adverse Events grade three or grade four toxicities will suffice, plus any unexpected toxicity not known to be associated with the drug being investigated. Finally, medical history and concomitant medications, which may be important to document drug interactions with an experimental treatment, serve no useful purpose in investigator-led trials. All in all, investigator-led trials should collect radically simpler data than industry-sponsored trials.
In terms of safety, investigator-led trials can collect much simpler data than industry-sponsored trials of drugs for which safety has not yet been demonstrated. Typically, in investigator-led trials, the occurrence of Common Terminology Criteria for Adverse Events grade three or grade four toxicities will suffice, plus any unexpected toxicity not known to be associated with the drug being investigated. Finally, medical history and concomitant medications, which may be important to document drug interactions with an experimental treatment, serve no useful purpose in investigator-led trials. All in all, investigator-led trials should collect radically simpler data than industry-sponsored trials.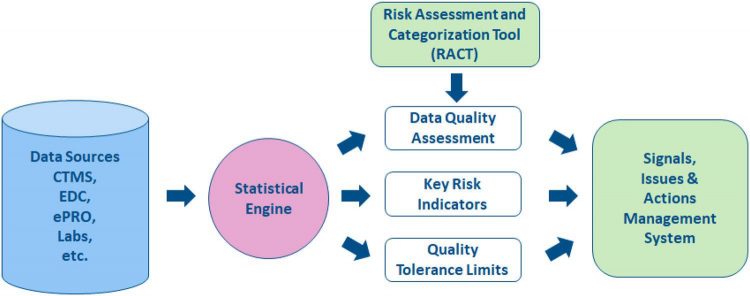


![Close up view of the Merck logo on the top corner of a glass building [Credit: Michael Vi / Shutterstock.com].](https://www.europeanpharmaceuticalreview.com/wp-content/uploads/Merck-aquisition-400x187.jpg)